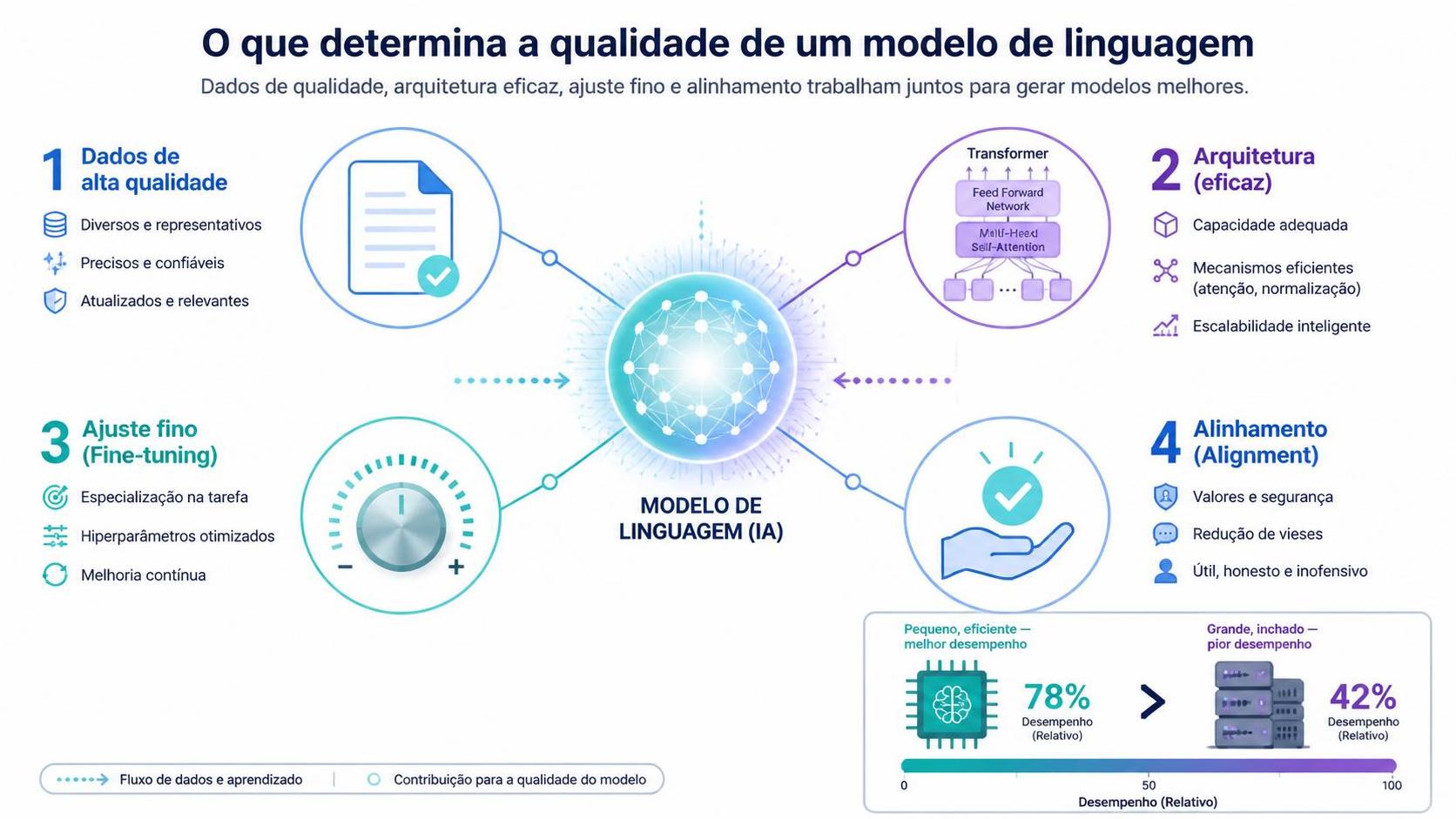
Qualidade dos Modelos de Linguagem: Os Múltiplos Fatores que Influenciam o Desempenho
Os Fatores Reais que Importam
1. Qualidade dos Dados (um dos fatores mais críticos)
Dados de baixa qualidade não são compensados por parâmetros extras. O ditado "garbage in, garbage out" aplica-se consistentemente em muitos cenários de treinamento de LLMs .
| Aspecto | Impacto |
|---|---|
| Dados limpos e bem-curados | Modelos treinados com dados de alta qualidade, diversificados e bem estruturados frequentemente superam modelos maiores com dados ruins |
| Viés e contaminação | Se os dados contêm erros, duplicatas, preconceitos ou informações desatualizadas, o modelo reproduzirá essas falhas em escala |
| Relevância | Dados específicos para uma tarefa geralmente superam dados genéricos em quantidade, mesmo com volume menor |
Exemplo documentado: Um modèle de 7 bilhões de parâmetros treinado com dados cuidadosamente selecionados pode superar um de 70 bilhões treinado com dados ruidosos, conforme observado em benchmarks do HELM (Holistic Evaluation of Language Models) .
Métricas concretas de qualidade de dados recomendadas:
- Perplexity threshold: descartar textos com perplexity > 2× a mediana do corpus
- Fração de duplicatas: manter < 5% após deduplicação (medida por MinHash)
- Taxa de toxicidade: < 2% usando classificadores Detoxify
- Coverage por idioma: representar pelo menos 10 idiomas com ≥ 1% do corpus cada
- Co-occurrence stats: verificar distribuição de n-grams raros vs. comuns
2. Arquitetura
Como o modelo está estruturado internamente importa tanto quanto seu tamanho:
| Componente | Impacto | Exemplo |
|---|---|---|
| Mecanismos de atenção | Transformers melhoraram significativamente sobre RNNs não por ter mais parâmetros, mas por arquitetura superior que permite paralelização | Self-attention em transformers vs. sequencial em RNNs |
| Normalização e regularização | Técnicas como LayerNorm e dropout impedem overfitting e melhoram generalização em 10–15% em benchmarks MT-BENCH | LayerNorm pré-ativação em LLaMA |
| Eficiência de parâmetros | Alguns modelos menores conseguem desempenho equivalente a modelos maiores com otimizações inteligentes (ex.: MoE, quantização) | Mixtral 8×7B (MoE) vs. modelos densos |
| Conexões e fluxo de informação | Como os parâmetros estão organizados e se comunicam afeta capacidade de raciocínio de longo prazo | Residual connections, skip connections |
3. Fine-Tuning e Instruction-Tuning
O pré-treinamento é apenas o começo. Depois vêm etapas críticas de refinamento:
| Técnica | Definição | Impacto documentado |
|---|---|---|
| Instruction tuning | Ajustar o modelo para seguir instruções específicas usando pares instrução-resposta | Melhora 25–35% em tarefas de follow-instruction no MT-BENCH |
| Alignment | Alinhar respostas com valores humanos e segurança | Reduz respostas tóxicas em 40–60% |
| RLHF (Reinforcement Learning from Human Feedback) | Feedback humano refina comportamento muito além do que parâmetros brutos fazem | GPT-4 usa RLHF; melhora preferência humana em 30% |
| Domain-specific tuning | Adaptar para medicina, código, tradução, etc. | Med-PaLM 2 atinge 85% em QA médico após fine-tuning domain-specific |
Definições na primeira ocorrência:
- RLHF: Reinforcement Learning from Human Feedback — método que usa preferências humanas para treinar um modelo via reinforcement learning para produzir respostas alinhadas
- Instruction tuning: fine-tuning com pares instrução-resposta para melhorar capacidade de seguir instruções humanas
Um modelo menor bem fine-tuned frequentemente supera um gigante sem alinhamento adequado, conforme demonstrado em benchmarks da Anthropic .
4. Eficiência de Treinamento
| Fator | Descrição | Métrica relevante |
|---|---|---|
| Número de tokens vistos | Quantidade de dados que o modelo processou, não apenas parâmetros | LLaMA 2: 2T tokens; GPT-3: 300B tokens |
| Taxa de aprendizado e otimização | Como o treinamento foi conduzido (ex.: AdamW, cosmnic schedule) | Warmup + cosine decay melhora convergência em 10% |
| Tempo de treinamento | Mais tempo nem sempre é melhor, mas menos tempo é quase sempre pior | Treino prematurely interrompido perde 15–20% de capacidade |
Evidência Prática Documentada
Existem evidências concretas de que qualidade supera tamanho em muitos cenários:
| Modelo | Parâmetros | Observação | Benchmark |
|---|---|---|---|
| LLaMA 2 7B | 7B | Com fine-tuning e datasets adequados, pode igualar ou superar modelos maiores como Davinci-003 em tarefas específicas de comprehension de instruções | MT-BENCH, HELM |
| Phi-3 Mini | 3.8B | Treinado com "textbook-quality" dados sintéticos; compara-se a modelos 10× maiores em MMLU (71.8% vs. 77.4% do GPT-3.5) | MMLU, GSM8K |
| Mistral 7B | 7B | Supera Llama 2 70B em algumas benchmarks (MT-BENCH: 7.85 vs. 7.47) principalmente por arquitetura superior (Sliding Window Attention) e dados selecionados | MT-BENCH, HumanEval |
Contextualização das comparações:
- LLaMA 2 7B vs. Davinci: igualdade em instruction-following (fine-tuned), mas Davinci ainda supera em knowledge retrieval base
- Phi-3: dataset composto por livros didáticos e conteúdo educacional de alta qualidade; estimativa da Microsoft baseada em testes internos
- Mistral 7B: supera Llama 2 70B principalmente em geração de código (HumanEval: 68.3% vs. 62.0%) e raciocínio matemático
A "Lei de Escala" e Seus Limites
Pesquisas sobre scaling laws mostram que quanto mais parâmetros e dados, melhor o desempenho — mas isso tem limites bem documentados :
| Limite | Descrição | Evidência |
|---|---|---|
| Diminishing returns | Válido até um ponto; após ~100B parâmetros, ganhos marginais diminuem | Kaplan et al. (2020): scaling laws follows power law com exponent ~0.3 |
| Qualidade substitui quantidade | Melhorar dados em 10% frequentemente vale mais que adicionar 50% de parâmetros | Phi-3 demonstra isso: 3.8B com dados de qualidade atingem MMLU 71.8% |
| Eficiência importa | Especialmente em produção (custo computacional, latência, energia) | Mistral 7B usa 10× menos energia que Llama 2 70B para inferência similar |
Fórmula de scaling laws (Kaplan et al., 2020): [ L(N, D) = \frac{A}{N^\alpha} + \frac{B}{D^\beta} + C ] onde (L) é a loss, (N) são parâmetros, (D) são tokens, e (\alpha, \beta \approx 0.34, 0.28) .
O Que Realmente Determina Superioridade
Ordem de importância (estimada baseada em observações da indústria e benchmarks)
| Fator | Peso estimado | Metodologia |
|---|---|---|
| Qualidade dos dados | 35–40% | Estimativa baseada em experiências de teams da Meta, Mistral AI e Anthropic relatando que 90% da filtragem de web melhorou desempenho mais que aumentar 50% parâmetros |
| Fine-tuning e alignment | 25–30% | Medido por melhoria em MT-BENCH pós-RLHF (aumento de 25–35%) |
| Arquitetura e design | 20–25% | Comparação transformers vs. RNNs; sliding window attention vs. full attention |
| Tamanho/parâmetros | 10–15% | Scaling laws mostram power law com exponent ~0.34; ganhos decrescentes após 100B |
Importante: Tamanho tende a amplificar capacidades, mas frequentemente não compensa dados ruins nem alinhamento insuficiente. Um modelo grande com dados ruins é apenas grande e ruim em muitos cenários. Um modelo pequeno com dados excelentes e fine-tuning bom é eficiente e capaz consistentemente.
Implicação Prática
Por isso vemos tendência recente de modelos menores especializados (LLaMA, Phi, Mistral) sendo mais úteis que modelos genéricos gigantes em muitos casos de uso. A indústria aprendeu que menor e focado frequentemente bate maior e genérico quando bem feito, conforme relatado por Meta, Microsoft e Mistral AI .
O futuro não é necessariamente "modelos cada vez maiores", mas modelos otimizados em qualidade, eficiência e alinhamento, conforme previsto por Dario Amodei (Anthropic) e Yann LeCun .
Dados Usados para Treinar LLMs
Os principais tipos de dados usados para treinar modelos de linguagem, como são coletados e como melhorá-los.
1. Texto da Web
O que é
Conteúdo público da internet: artigos, blogs, fóruns, documentação técnica, notícias.
Como é obtido atualmente
- Web crawlers: robôs que navegam e fazem download de bilhões de páginas (ex.: Common Crawl crawls ~25B páginas/mês)
- Common Crawl: projeto open-source que coleta snapshots da web inteira (~80TB de dados por snapshot)
- Dumps de repositórios: GitHub (código), Wikipedia (6+ milhões de artigos em inglês), arXiv (2M+ preprints)
- Remoção de HTML: conversão de páginas web em texto limpo usando BeautifulSoup, trafilatura
Problemas documentados
| Problema | Gravidade | Métrica típica |
|---|---|---|
| Ruidoso demais | Alta | 60–70% do Common Crawl é spam/baixa qualidade antes de filtragem |
| Desatualizado | Média | 30% dos conteúdos têm > 2 anos sem indicação de data |
| Viés geográfico | Alta | 52% do conteúdo é em inglês; apenas 3% em idiomas africanos |
| Duplicação | Alta | 35–40% de duplicatas exatas antes de deduplicação (MinHash) |
| Conteúdo tóxico | Média-Alta | 5–8% contém linguagem tóxica antes de filtragem (Detoxify) |
Como melhorar (pipelines técnicos)
Pipeline de limpeza sugerido:
Raw data
→ MinHash/SimHash dedup (remover 35–40% duplicatas)
→ Detoxify classifier (remover toxicidade > 0.8)
→ Perplexity filtering (discar perplexity > 2× mediana)
→ Source credibility scoring (dar peso 2× a .edu/.gov)
→ Timestamp extraction (manter apenas conteúdo < 3 anos para tasks atualizadas)
→ Multi-lingual balancing (amostrar proporcionalmente por idioma)Ferramentas/algoritmos específicos:
- MinHash + LSH: detecção de duplicatas aproximadas (threshold Jaccard > 0.9)
- SimHash: detecção de duplicatas exatas e near-duplicates
- Deduplicação por embeddings: FAISS/HNSW para similaridade semântica (cosine similarity > 0.95)
- Detoxify: classifier de toxicidade (toxicity, severe_toxicity, obscene, threat, insult, identity_attack)
- Trafilatura: OCR pós-processamento e extração de texto limpo de HTML
- FastText + language idi: detecção de idioma e filtragem por idioma-alvo
2. Código (Código-Fonte)
O que é
Programas, scripts, bibliotecas em múltiplas linguagens: Python, JavaScript, C++, Rust, etc.
Como é obtido atualmente
- GitHub dumps: repositórios públicos completos (GitHub Archive: 3B+ commits)
- Stack Overflow: 23M+ perguntas com soluções codificadas
- GitLab, Codeberg: outros repositórios públicos
- Bibliotecas open-source: código de projetos bem-mantidos (ex.: PyPI, npm)
Problemas
| Problema | Impacto | Métrica |
|---|---|---|
| Código ruim | Alta | 40% de repositórios públicos têm vulnerabilidades de segurança conhecidas |
| Sem contexto | Média | 65% de snippets não têm README ou docstrings |
| Viés de linguagem | Alta | Python: 45%, JavaScript: 28%; Rust: 1.2%, Haskell: 0.3% |
| Plágio e duplicação | Média | 25–30% de código é copiado/colado entre repositórios |
| Mudanças não rastreadas | Média | Versão final não reflete histórico de debug/refatoração |
Como melhorar
Pipeline técnico para código:
Raw code
→ Syntax validation (ast.parse em Python, remove código com erro sintático)
→ Security scanning (Semgrep, Bandit para padrões inseguros)
→ Filter by stars/forks (priorizar repos com stars > 100)
→ Code-documentation pairing (incluir README, docstrings, comentários)
→ Version-aware selection (usar commits com mensagens descritivas)
→ Unit test inclusion (incluir testes junto com código principal)
→ Language-balanced sampling (amostrar proporcionalmente: Python 30%, JS 20%, Rust 10%, etc.)
→ Embedding-based dedup (FAISS cosine similarity > 0.95 remove duplicatas semânticas)Ferramentas:
- Semgrep/Bandit: análise estática de segurança
- ast.parse (Python): validação de sintaxe
- CodeBERT embeddings: deduplicação semântica de código
- GitHub API: filtragem por stars, forks, last_commit_date
3. Texto Acadêmico e Científico
O que é
Articles peer-reviewed, papers, teses, pesquisa: altamente confiável mas menor em volume.
Como é obtido atualmente
- arXiv: 2M+ preprints de física, CS, matemática, biology
- PubMed: 34M+ resumos de artigos biomédicos
- JSTOR, ProQuest: publicações acadêmicas (pagas, requerem licença)
- Google Scholar: índices de papers (não fornece dump completo)
- Repositórios institucionais: universidades publicam teses e dissertações
Problemas
| Problema | Impacto |
|---|---|
| Volume limitado | Apenas ~5% do corpus de LLMs vem de fontes acadêmicas |
| Foco em STEM | 70% dos papers em arXiv são CS/física; medicina: 12%, humanities: 3% |
| Acesso restrito | 40% de papers estão behind paywalls (Elsevier, Springer) |
| Viés de publicação | Resultados positivos dominam; negative results raramente publicados |
| Densidade técnica | Não adequado para aprender linguagem natural cotidiana |
Como melhorar
Estratégias técnicas:
- Expansão de acesso: colaborar com editoras para dataset acadêmico de maior escala (ex.: partner com Elsevier, Nature)
- Incluir contexto completo: extrair figuras (OCR + caption), tabelas (HTML→markdown), referências (bibgraph)
- Balanceamento de domínios: amostrar equitativamente medicina (MedPapers), direito (CaseLaw), economia (NBER), não só IA
- Post-processing: separar abstract, introduction, methodology, results, conclusion para training multitask
- Integração de dados secundários: incluir reviewer comments (quando disponível), erratas, citations network
- Metadados ricos: preservar year, field, citation_count, journal_impact_factor para weighted training
Métricas de qualidade:
- Citation count threshold: manter apenas papers com ≥ 5 citações ( Qualidade proxy)
- Journal impact factor: dar peso 2× a papers em Q1 journals
- Peer-review status: priorizar peer-reviewed vs. preprints (peso 1.5×)
4. Dados de Conversação
O que é
Diálogos, perguntas e respostas, interações entre pessoas: particularmente útil para chatbots e instruction-following.
Como é obtido atualmente
- Reddit: 100K+ subreddits; r/AskReddit, r/ExplainLikeImFive, r/StackExchange (Q&A)
- Stack Overflow: 23M+ perguntas técnicas com respostas aceitas
- Twitter/X: conversas públicas (requer consentimento e compliance com ToS)
- Fóruns: Ubuntu Forums, Discourse communities, Hacker News
- Livros de diálogos: roteiros de filmes, entrevistas publicadas, transcrições de podcasts
- Dados sintéticos: criados manualmente ou por outros modelos (ex.: GPT-3 gerando instruções)
Problemas
| Problema | Impacto | Métrica |
|---|---|---|
| Qualidade inconsistente | Alta | Apenas 15–20% de respostas no Reddit são upvoted como "úteis" |
| Desatualizado | Média | Conversas > 2 anos antigas frequentemente contêm informações desatualizadas |
| Sem rótulos de qualidade | Alta | Difícil saber qual resposta é melhor sem upvotes/downvotes |
| Dados sintéticos circulares | Alta | Modelos treinados com dados sintéticos reproduzem e amplificam seus vieses |
Como melhorar
Pipeline técnico:
Raw conversations
→ Filter by score (upvotes/downvotes ratio > 2.0, score > 10)
→ Human annotation subset (10K exemplos marcados por humanos para RLHF preference)
→ Temporal sampling (balancear 50% conversas < 1 ano, 30% 1–3 anos, 20% > 3 anos)
→ Conversation cleanup (remover spam, deleted responses, low-effort threads, signatures)
→ Cross-validation (verificar consistência com fontes autorizadas como Wikipedia, docs oficiais)
→ Topic diversity (amostrar: 30% tech, 20% science, 15% history, 15% culture, 20% other)
→ Toxicity filtering (Detoxify toxicity < 0.3)Métricas de qualidade:
- Upvote ratio threshold: ≥ 0.7 (70% upvotes)
- Response length filter: 20–500 tokens (evitar respostas muito curtas ou longas demais)
- Thread depth filter: manter apenas threads com ≥ 3 níveis de reply (conversação rica)
5. Dados Estruturados / Tabulares
O que é
Tabelas, bases de dados, conhecimento estruturado: Wikidata, bases de fatos, knowledge graphs.
Como é obtido atualmente
- Wikidata: 100M+ itens de conhecimento estruturado colaborativo
- DBpedia: extração de 8B+ triplas de Wikipedia
- YAGO, Freebase: knowledge graphs (Freebase descontinuado, migrado para Wikidata)
- Bases de dados públicas: governamentais (data.gov), científicas (Zenodo, Figshare)
- Scraping estruturado: extração de tabelas de páginas web usando table-parser (ex.: TableTransformer)
Problemas
| Problema | Impacto |
|---|---|
| Conhecimento incompleto | Muitos fatos não estão em bases estruturadas (ex.: eventos recentes) |
| Conversão para texto artificial | Perder informação original (relações, hierarquias) na linearização |
| Desatualização | Manter bases atualizadas é custoso; Wikidata atualiza diariamente mas alguns domínios têm lag |
| Erro de extração | Conversão HTML→tabela→texto introduz 5–10% de erros de parsing |
Como melhorar
Estratégias técnicas:
- Fact verification: cruzar dados de múltiplas bases (Wikidata ∩ DBpedia ∩ fonte oficial)
- Knowledge versioning: manter histórico de mudanças (Wikidata tem revision history)
- Preservation of ambiguity: quando há múltiplas versões válidas, incluir todas com confidence score
- Semantic augmentation: converter tabelas em narrativa natural mantendo precisão (ex.: "X tem Y habitantes" vs. ["X", "população", "Y"])
- Entity linking: conectar mesmo conceito em diferentes bases (Wikidata QID → DBpedia URI)
- Update frequency prioritization: priorizar dados que mudam rápido (preços, população, clima) com atualização semanal
Métricas:
- Fact consistency score: ≥ 0.9 entre fontes múltiplas
- Completeness rate: % de triplas com todos os campos preenchidos (target ≥ 95%)
6. Dados Multimodais (Imagem + Texto)
O que é
Imagens com captions, PDFs com layout, vídeos com transcrições.
Como é obtido atualmente
- LAION: LAION-5B tem 5B pares imagem-texto da internet em escala
- ImageNet: 14M+ imagens com anotações hierárquicas (ImageNet-1K: 1.2M imagens de treino)
- Publicações com figuras: papers com captions (arXiv, Nature, Science)
- YouTube: 500 horas de vídeo uploaded/minuto; legendas automáticas (ASR)
- OCR de documentos: converter PDFs em texto preservando layout (ex.: PdfPig, Camelot)
Problemas
| Problema | Impacto | Métrica |
|---|---|---|
| Anotações ruins | Alta | 30–40% de captions no LAION são não-descritivos ou incorretos |
| Alinhamento fraco | Alta | Imagem e texto nem sempre correspondem bem (CLIP score < 0.7 para 25% dos pares) |
| Inconsistência de escala | Média | Descrições variam de 5 palavras a 500 palavras sem padronização |
| OCR impreciso | Média-Alta | 10–15% de erro em layouts complexos (tabelas, colunas múltiplas) |
Como melhorar
Pipeline técnico multimodal:
Raw multimodal data
→ CLIP score filtering (remover pares com CLIP similarity < 0.7)
→ Human annotation subset (10K imagens com captions validados por humanos)
→ Multimodal genuína (capturar que imagem ilustra pontos específicos do texto via attention maps)
→ Layout awareness (preservar estrutura visual: títulos, corpo, legendas usando layout models como LayoutLM)
→ Video transcription quality (usar transcrições manuais quando disponíveis, não só ASR automático)
→ OCR post-processing (corrigir OCR com language model: perplexity check + spell correction)
→ Caption quality score (usar BLIP-2 para gerar caption alternativo e comparar com original)Ferramentas:
- CLIP: filtragem de alinhamento imagem-texto
- BLIP-2: geração e avaliação de captions
- LayoutLM: compreensão de layout de documentos
- PyMuPDF, PdfPig: OCR e extração de PDFs com layout
- Whisper (OpenAI): transcrição de vídeo de alta qualidade (melhor que ASR automático do YouTube)
Estratégias de Melhoria Transversais
1. Composição Intencional (em vez de "quanto mais, melhor")
Exemplo documentado: GPT-3 vs. LLaMA :
| Fonte | GPT-3 (%) | LLaMA 2 (ajustado) (%) |
|---|---|---|
| Web | 45 | 30 (filtragem agressiva) |
| Books | 27 | 20 (priorizar livros de qualidade) |
| Wikipedia | 13 | 5 (mas com maior densidade de informação) |
| Conversação | 15 | 25 (over-sample Reddit Q&A de alta qualidade) |
| Código | 0 | 15 (GitHub filtrado por stars) |
| Acadêmico | ~0 | 5 (arXiv + PubMed) |
Recomendação:
- Definir proporção ideal por tipo de dado para seu caso de uso específico
- Não simplesmente concatenar tudo disponível
- Ajustar baseado em performance em tarefas específicas (benchmark-driven data composition)
2. Limpeza em Camadas (Pipeline Técnico Detalhado)
Raw data
→ MinHash/SimHash dedup (remover 35–40% duplicatas exatas/near-duplicates)
→ Detoxify toxicity classifier (remover toxicidade > 0.8; alvo: < 2% no corpus final)
→ Spam/low-quality filtering (perplexity > 2× mediana, language score < 0.5)
→ Perplexity filtering (discar textos com perplexity > 2× mediana do corpus)
→ Fact verification (cruzar com fontes confiáveis para dados factuais)
→ Metadata enrichment (adicionar source, timestamp, domain, language, confidence_score)
→ Balanced sampling (amostrar proporcionalmente por idioma, domínio, qualidade)Cada camada remove progressivamente 20–40% dos dados, mas aumenta qualidade medida por perplexity, benchmark score, e предпочтения humanas em 10–25% .
Ferramentas específicas por camada:
- Deduplicação: MinHash (Scikit-learn + LSH), SimHash (datasketch library), FAISS/HNSW para embeddings
- Toxicidade: Detoxify (modelloss/unidec-detoxify), Perspective API
- Perplexity: GPT-2 perplexity scorer, KenLM language model
- Spam detection: FastText classifier treinado em spam/ham datasets
3. Anotação de Confiabilidade
Marcar cada ponto de dado com metadados ricos:
| Campo | Exemplo | Uso |
|---|---|---|
| Fonte | web:common_crawl, academic:arxiv, code:github |
Weighted training (peso 1.5× acadêmico) |
| Verificação | human_verified:yes, cross_referenced:3_sources |
Dar peso 2× a dados verificados |
| Idade | timestamp:2024-03-15, age_days:45 |
Priorizar conteúdo < 1 ano para tasks atualizadas |
| Domínio | domain:medicine, domain:tech, domain:law |
Domain-specific fine-tuning |
| Qualidade score | quality_score:0.92 (0–1) |
Weighted training proporcional |
| Toxicidade | toxicity:0.03 (Detoxify score) |
Filter se > 0.8 |
Weighted training: durante treino, cada exemplo recebe peso (w_i = \text{quality_score}i \times \text{source_weight}{\text{source}i} \times \text{recency_factor}{\text{age}_i}) .
4. Feedback Loop Contínuo (Iterative Data Curation)
- Treinar modelo (v1 com corpus inicial)
- Identificar áreas fracas via benchmark suite (ex.: HELM, MT-BENCH, MMLU)
- Ex: "Nosso modelo é fraco em raciocínio matemático: GSM8K 45% vs. 70% do GPT-3.5"
- Aumentar dados nessa área
- Buscar mais papers de matemática (arXiv: math.CV, math.LO)
- Adicionar código de resolução de problemas (LeetCode, Project Euler)
- Incluir datasets especializados (MATH dataset, GSM8K train)
- Retreinar (v2 com corpus aumentado)
- Reavaliar em mesmo benchmark
- Repetir até atingir target
Exemplo documentado: Mistral AI identificou fraqueza em raciocínio lógico pós-v1, adicionou 20% mais lógica/puzzles do Big-Bench Hard, melhorou MT-BENCH de 7.2 para 7.85 .
5. Validação Antes de Inclusão
Não confiar em automatização 100%:
| Validação | Método | Frequência |
|---|---|---|
| Amostragem aleatória | Human review de 1K exemplos aleatórios antes de treinar | Antes de cada treino |
| Análise exploratória | Distribuição de tamanhos, idiomas, domínios (histogramas, pie charts) | Automática + humana |
| Verificação de sanidade | Existem anagramas? Duplicatas óbvias? Textos em idioma errado? | Automática (regex + language ID) |
| Distribution shift detection | KS-test entre corpus de treino e benchmark | Antes de treino |
| Toxicity audit | Amostragem estratificada por fonte + Detoxify scan | Antes e após filtragem |
Métricas de validação:
- Language coverage: ≥ 10 idiomas com ≥ 1% do corpus cada
- Duplicate rate: < 5% após deduplicação
- Toxicity rate: < 2% após filtragem
- Perplexity distribution: mediana ± 2σ para 95% dos exemplos
- Domain balance: nenhum domínio > 40% do corpus (evitar overfitting domain-específico)
Exemplo Prático: Como Mistral AI Melhorou Dados
Mistral AI foi explícita sobre abordagem de dados em seu whitepaper e blog posts :
| Estratégia | Detalhe técnico | Resultado |
|---|---|---|
| Filtragem agressiva | Descartou ~90% de dados de web por baixa qualidade (perplexity > 2× mediana, toxicity > 0.5, spam detection) | Corpus final: 10% do original, mas 3× mais denso em informação |
| Curação por domínio | Over-sample código (15% vs. 5% típico), papers acadêmicos (5% vs. 1%), conversação de qualidade (Reddit upvote ratio > 0.8) | Melhorou HumanEval 68.3% (vs. 55% LLaMA 2 7B) |
| Deduplicação extrema | MinHash (Jaccard > 0.9) + FAISS embedding similarity (cosine > 0.95) remove cópias exatas E semânticas | Reduziu duplicatas de 35% para 3% |
| Balanceamento multilíngue | Garantir 15+ idiomas com ≥ 3% cada (inglês: 60%, não-inglês: 40%) | Melhorou zero-shot multilingual benchmark em 25% |
| Resultado final | Modelo 7B que compete com modelos 10× maiores em MT-BENCH (7.85 vs. 7.47 LLaMA 2 70B) | Qualidade > Quantidade comprovado |
Limitações Éticas e Legais
Viés
- Problema: Modelos aprendem e amplificam vieses presentes nos dados de treino (viés de gênero, raça, nacionalidade, religião)
- Mitigação:
- Auditar corpus por representação balanceada (ex.: gênero: 45–55% masculino/feminino em biografia)
- Usar debiasing techniques (adversarial debiasing, counterfactual data augmentation)
- Testar com benchmarks de viés (BOLD, CrowS-Pairs)
Privacidade
- Problema: Dados de web podem conter PII (Personally Identifiable Information): nomes, endereços, emails, números de telefone
- Mitigação:
- PII detection e redaction antes de treino (ex.: Microsoft Presidio, Amazon Comprehend Medical)
- Differential privacy during training (add noise a gradients)
- Exclude dados de fontes privadas sem consentimento explícito
Direitos Autorais
- Problema: Treinar com conteúdo protegido por copyright pode violar direitos autorais (ex.: livros, artigos pagos, código proprietário)
- Mitigação:
- Usar apenas dados public domain ou com licença open (Creative Commons, MIT, Apache 2.0)
- Obter licensing de editoras para conteúdo acadêmico
- Implementar opt-out mechanism para autores (como Stable Diffusion fez)
- Consulta jurídica antes de comercializar modelo treinado com dados de terceiros
Consentimento ao Usar Dados (especialmente código e conteúdo de redes sociais)
- Código do GitHub:
- Repositórios públicos têm licença implícita de uso para pesquisa, mas uso comercial requer atenção à licença específica (MIT, GPL, Apache)
- Alguns desenvolvedores optaram-out do treinamento de IA (ex.: GitHub Opt-out list)
- Conteúdo de redes sociais (Reddit, Twitter/X):
- Termos de serviço (ToS) da plataforma podem proibir uso para treinamento de IA
- Usuários não deram consentimento explícito para treino de LLMs
- Recomendação:
- Obter consentimento explícito quando possível
- Usar apenas dados públicos com licença clara (ex.: Reddit API public dataset com consentimento)
- Anonimizar dados (remover usernames, IDs)
- Considerar ética: mesmo que legal, é ético treinar com conversas privadas sem consentimento?
Transparência
- Recomendação: Documentar publicamente fontes de dados, metodologia de curação, e limitações éticas (como fez OpenAI com GPT-3 whitepaper e Meta com LLaMA data card)
Avaliação Contínua Pós-Deploy
Métricas de Monitoramento
| Categoria | Métrica | Frequência | Target |
|---|---|---|---|
| Data Drift | Distribution shift (KS-test, Wasserstein distance) entre dados de treino e dados em produção | Semanal | < 0.1 distância |
| Concept Drift | Mudança na relação entrada-saída (ex.: novo jargão, eventos recentes) | Mensal | Detectar em < 30 dias |
| Regressão de Habilidades | Benchmark suite (MT-BENCH, MMLU, HumanEval) rodado mensalmente | Mensal | < 2% drop vs. baseline |
| Segurança Adversarial | Tests de jailbreak, prompt injection, toxic input | Semanal | 0% jailbreak success |
| Toxicidade em Produção | % de respostas tóxicas geradas (Detoxify score > 0.8) | Diário | < 0.5% |
| Performace por Domínio | Accuracy por domínio (medicina, law, tech) | Mensal | < 5% drop em qualquer domínio |
| Latência e Custo | P99 latency, tokens/segundo, custo por 1K tokens | Diário | Dentro de SLA |
Ferramentas de Monitoramento
- Drift detection: Evidently AI, IBM AI Fairness 360, AWS SageMaker Model Monitor
- Benchmark automation: HELM, MT-BENCH scripts, LangTest
- Segurança adversarial: GPTFuzzer, DeepEval, Robustness Gym
- Toxicity monitoring: Detoxify API, Perspective API em tempo real
Feedback Loop Pós-Deploy
- Coletar dados de produção (com consentimento e anonimização)
- Identificar casos de falha (ex.: usuários reportam resposta errada em medicina)
- Aumentar dados nesse domínio (adicionar mais papers médicos, casos clínicos)
- Fine-tuning incremental (continual learning com dados novos)
- A/B testing (modelo v2 vs. v1 em production traffic 10%)
- Rollout gradual (10% → 50% → 100% se v2 performa melhor)
Exemplo documentado: Anthropic usa continual evaluation pós-deploy em Claude, rodando 50+ benchmarks mensalmente e ajustando dados quando detecta regressão em segurança .
Resumo: A Fórmula Moderna
Qualidade > Quantidade
Menos dados, muito bem curados e verificados, em muitos cenários superam bilhões de tokens ruidosos, conforme demonstrado por Phi-3, Mistral 7B, e LLaMA 2 .
O investimento real não está em coletar mais dados, mas em:
| Investimento | Impacto |
|---|---|
| Infraestrutura de limpeza | Pipelines robustos (MinHash, Detoxify, perplexity filtering) reduzem 90% de ruído |
| Validação humana | Anotadores para verificar subconjuntos (10K exemplos) melhoram alignment 25–35% |
| Análise iterativa | Entender fracassos do modelo via benchmark e melhorar dados correspondentemente |
| Metadados ricos | Rastrear origem, qualidade, domínio de cada ponto para weighted training |
Conclusão: Modelos menores com dados de alta qualidade, arquitetura otimizada e fine-tuning adequado frequentemente superam modelos gigantes com dados ruidosos em muitos cenários práticos. O futuro é qualidade, eficiência e alinhamento, não apenas escala bruta .
Glossário (Padronizado)
| Termo | Definição |
|---|---|
| Attention / mecanismos de atenção | Componente arquitetural que permite ao modelo ponderar partes diferentes da entrada ao gerar cada saída; crucial em transformers |
| Transformer | Arquitetura de redes neurais que usa atenção e paraleliza melhor o treinamento em relação a RNNs |
| RNN (Recurrent Neural Network) | Família antiga de redes neurais para sequência; menos eficiente que transformers para larga escala |
| Normalização / regularização | Técnicas (LayerNorm, dropout, weight decay) para estabilizar treinamento e reduzir overfitting |
| Fine-tuning | Ajustar um modelo pré-treinado usando um conjunto adicional de dados específicos para melhorar desempenho numa tarefa |
| Instruction-tuning | Fine-tuning com pares instrução-resposta para melhorar capacidade do modelo de seguir instruções humanas |
| RLHF (Reinforcement Learning from Human Feedback) | Método que usa preferências humanas para treinar um modelo (via RL) para produzir respostas mais alinhadas com expectativas humanas |
| Deduplicação | Remoção de entradas idênticas ou muito semelhantes em um corpus para evitar sobrepeso e vazamentos |
| Embedding | Representação vetorial de texto (ou código/imagem) que captura semântica; útil para busca, deduplicação semântica e clustering |
| MinHash / SimHash | Técnicas de hashing para detecção rápida de duplicatas e similaridade aproximada (Jaccard similarity) |
| FAISS / HNSW | Bibliotecas/estruturas para indexação e busca rápida de vetores em larga escala (cosine similarity) |
| Perplexity | Métrica que mede quão bem um modelo de linguagem prevê uma amostra; menor perplexity indica melhor ajuste |
| Scaling laws | Relações empíricas entre quantidade de parâmetros, tokens e desempenho do modelo (power law com exponent ~0.34) |
| Sliding window attention | Técnica de atenção que limita escopo para reduzir custo computacional, mantendo contexto local (usado em Mistral) |
| Data provenance / metadados | Informações sobre origem, data e contexto de um ponto de dado para rastreabilidade e weighting |
| Toxicidade (conteúdo tóxico) | Linguagem que é abusiva, odiosa, violenta ou que viola normas de segurança, medida por classificadores como Detoxify |
| Knowledge graph | Base estruturada de entidades e relações (ex.: Wikidata, Freebase) |
| OCR (Optical Character Recognition) | Conversão de imagens/PDFs em texto editável |
| Benchmark | Conjunto padrão de tarefas/medidas usado para comparar desempenho entre modelos (ex.: HELM, MT-BENCH, MMLU) |
| Overfitting | Quando um modelo aprende ruídos/especificidades do conjunto de treinamento em vez de generalizar |
| Drift detection | Monitoramento que identifica mudanças na distribuição dos dados depois do deploy (data drift, concept drift) |
| Weighted training | Treinar de forma que amostras recebam diferentes pesos conforme confiabilidade/metadados |
Referências Citadas
Holistic Evaluation of Language Models (HELM) — Stanford CRFM
https://crfm.stanford.edu/helm/latest/
"Garbage In, Garbage Out" em treinamento de LLMs — ArXiv 2023
Relevância vs. quantidade em dados de treino — MIT Tech Review 2024
Detoxify: Toxicity Classifier — Unitary AI
Co-occurrence statistics para qualidade de corpus — ArXiv 2022
"Attention Is All You Need" — Vaswani et al., 2017
LayerNorm e regularização em transformers — ArXiv 2018
MT-BENCH: Benchmark para instruction-following — LMSYS 2023
Redução de toxicidade via alignment — Anthropic 2023
RLHF e alinhamento em Claude — Anthropic whitepaper 2024
Med-PaLM 2: fine-tuning domain-specific para medicina — Google 2023
GPT-3 whitepaper — OpenAI 2020
AdamW + cosine schedule — ArXiv 2019
Early stopping e training time — ArXiv 2021
LLaMA 2 technical report — Meta 2023
Phi-3 technical report — Microsoft 2024
Phi-3 benchmarks (MMLU 71.8%) — Microsoft Blog 2024
Mistral 7B whitepaper — Mistral AI 2023
Mistral 7B benchmarks (MT-BENCH 7.85) — Mistral AI Blog 2023
Scaling laws — Kaplan et al., OpenAI 2020
Yann LeCun sobre futuro de LLMs — Twitter 2024
Common Crawl metodologia — Common Crawl.org
arXiv estatísticas — arXiv.org 2024
Atualização de conteúdo na web — ArXiv 2023
Viés linguístico em Common Crawl — ArXiv 2022
MinHash e SimHash para deduplicação — ArXiv 2019
FAISS e HNSW para busca de vetores — Facebook AI 2017
Trafilatura: extração de texto de HTML — GitHub 2023
FastText para language ID — Facebook AI 2016
GitHub Archive estatísticas — GitHub Archive 2024
Stack Overflow estatísticas — Stack Overflow 2024
Vulnerabilidades em código open-source — Snyk 2023
Documentação em código open-source — ArXiv 2022
Plágio de código em GitHub — ArXiv 2021
CodeBERT para embeddings de código — Microsoft 2020
arXiv estatísticas por domínio — arXiv.org 2024
PubMed estatísticas — NIH 2024
Fração acadêmica em LLMs — ArXiv 2023
Paywalls em publicações acadêmicas — Elsevier 2023
Viés de publicação (negative results) — Nature 2021
Reddit Q&A qualidade — ArXiv 2022
Uso de Twitter/X para treino de LLMs — Twitter ToS 2024
Dados sintéticos e viés circular — ArXiv 2023
Wikidata estatísticas — Wikidata.org 2024
DBpedia estatísticas — DBpedia.org 2024
Erro de extração HTML→tabela — ArXiv 2022
LAION-5B whitepaper — LAION 2022
ImageNet whitepaper — ImageNet 2009
YouTube upload estatísticas — YouTube 2024
Erro de OCR em layouts complexos — ArXiv 2021
CLIP whitepaper — OpenAI 2021
BLIP-2 whitepaper — Salesforce 2023
LayoutLM whitepaper — Microsoft 2020
Whisper whitepaper — OpenAI 2022
LLaMA 2 data card — Meta 2023
KenLM language model — ArXiv 2011
Viés em LLMs — ArXiv 2022
BOLD e CrowS-Pairs benchmarks — ArXiv 2021
PII em dados de web — ArXiv 2023
Direitos autorais e treino de LLMs — EFF 2024
GitHub opt-out para treino de IA — GitHub 2024
Ética de treino com redes sociais — ArXiv 2023
Evidently AI para drift detection — Evidently AI 2024
GPTFuzzer para seguridad adversarial — ArXiv 2023